

README
“The
REFCODES.ORGcodes represent a group of artifacts consolidating parts of my work in the past years. Several topics are covered which I consider useful for you, programmers, developers and software engineers.”
What is this repository for?
This artifacts provides you means to produce high throughput of symmetric encryption of data securing it with an asymmetric encryption approach - giving you the speed of symmetric encryption and the security of asymmetric (public/private-key) encryption. It seamlessly works together with the refcodes-logger toolkit enabling you to log vast amounts of information in an effective and protected manner.
How do I get set up?
To get up and running, include the following dependency (without the three dots “…”) in your pom.xml:
1
2
3
4
5
6
7
8
9
<dependencies>
...
<dependency>
<groupId>org.refcodes</groupId>
<artifactId>refcodes-forwardsecrecy</artifactId>
<version>3.3.5</version>
</dependency>
...
</dependencies>
The artifact is hosted directly at Maven Central. Jump straight to the source codes at Bitbucket. Read the artifact’s javadoc at javadoc.io.
Introduction
The
refcodes-forwardsecrecyartifact provides a framework for easy encryption and decryption functionality with a high throughput.
The design is strictly using separation of concerns regarding encryption functionality and decryption functionality. This framework is designed to perform encryption and decryption on huge amounts of data. Therefore a symmetric cryptography approach (fast) is used for encryption and decryption purposes, being combined with an asymmetric cryptography approach (secure) for symmetric cipher exchange.
Security is increased with the support of continuously changing the symmetric ciphers, similar to the Forward Secrecy approach!
 |
|---|
Fancy output of a refcodes-forwardsecrecy driven service |
Various REFCODES.ORG artifacts make use of the refcodes-forwardsecrecy framework, for example the refcodes-tabular-alt-forwardsecrecy artifact.
How do I get started?
To get started I list the requirements I had in mind when I was designing the refcodes-forwardsecrecy artifact:
- We have to store big-data in a secure though fast manner
- We also have to retrieve big-data in a secure though fast manner
- Decryption parts and encryption parts are to be strictly separated from each other to enable operation of physically separated encryption and decryption systems (servers)
- Encrypting parts are to generate their symmetric ciphers (for encryption and decryption) by themselves, volatile, in-memory, and exclusively for their own (in-memory) use only, encryption must not persist symmetric ciphers
- Decryption parts are to use the (decrypted) symmetric ciphers in-memory, volatile, and exclusively for their own (in-memory) use only. Conclusion: A pure asymmetric encryption approach is far too slow when decrypting the data. Symmetric keys must not be accessible (on a physical storage) on the encrypting systems as plain text
Summary
This artifact provides a toolkit for easy encryption and decryption functionality with a high throughput.
The design is strictly using separation of concerns regarding encryption functionality and decryption functionality. This framework is designed to perform encryption and decryption on huge amounts of data. Therefore a symmetric cryptography approach (fast) is used for encryption and decryption purposes, being combined with an asymmetric cryptography approach (secure) for symmetric cipher exchange.
Having the requirements above in mind, the design approach behind the refcodes-forwardsecrecy toolkit may be summarized as follows:
- Each cipher belongs to a unique cipher
UID; which is generated alongside with the cipher; though completely independently from the cipher. The cipherUIDcan be public (is considered to be public) without causing any security issues - The tuple consisting of of cipher and cipher
UIDis managed as a so calledcipher version - The encryption parts use the public key of an asymmetric encryption approach to store the generated
cipher versions in a data store (file-system, repository) to be used by decryption parts owning the according private key - When encrypting data, the encryption parts encrypt the data with the cipher and prefix the cipher’s cipher
UIDto that data - The
cipher versions are stored in a data store (file-system, repository) for usage by an authorized decrypting parts owning the according private key - The decryption parts can read the encrypted
cipher versions from the data store (file-system, repository), decrypting it with their private key - The decrypted
cipher versions are only held in-memory by the decrypting parts - The decryption parts retrieve the data to be decrypted and extract the cipher
UIDfrom that data which has been prefixed before by the encryption parts to that data - Having the cipher
UIDthe decryption parts can look up the according cipher and decrypt the data - As many
cipher versions may get generated and persisted, housekeeping should be applied to outdatedcipher versions - The only use case when decryption and encryption is to be performed on the same system is when updating encrypted data which has been encrypted with an outdated cipher (a cipher
UIDmay contain the date of cipher creation or acipher versionmay contain an additional valid date attribute) - In such cases, only the outdated
cipher versions must be accessible by such an update (encryption and decryption) part as it generates its own valid encryption cipher - In case
cipher versions are unexpectedly disclosed, them will invalidate as soon as the according encrypted data has been updated by the update (encryption and decryption) part; using a newly generatedcipher version - That fresh
cipher versionis stored using the public key of an asymmetric encryption algorithm as of step 3 - A shortcoming is on how to securely provide such an update (encryption and decryption) part just with the outdated
cipher versions; whilst preventing access to the validcipher versions (technically, as seen below when looking at the design, this is no problem: Using a separate data store for outdated ciphers secured by a separate key-pair just requires the outdated ciphers to be moved to the alternate data store) - As so, the private key for decrypting the outdated
cipher versions must be different to the one which is used for decrypting the validcipher versions…
Discussion
This mechanism has the following obvious shortcomings: Having control over a decryption part makes all the data readable. Though when using asymmetric encryption, having access to a system with the private key has the same effect. As of performance reasons, the approach of managing symmetric ciphers separate from the data chunks to be processed and processing those symmetric ciphers with an asymmetric cryptography approach has been chosen:
The forward secrecy cryptography infrastructure as discussed here is to handle persistent data. Using a pure asymmetric encryption approach would not reduce the security hot spot. Furthermore the disadvantage of an asymmetric cryptography approach comes for many small chunks of data to be processed; even when used in combination with a symmetric cryptography approach (similar to the HTTPS handshake):
Processing small chunks of data either directly with an asymmetric cryptography approach or combined with a symmetric cryptography approach with post processing of the symmetric cipher for that chunk with an asymmetric cryptography approach costs execution time for each data chunk processed respectively; which is to a great extend slower than processing using a symmetric approach. The assumption behind it might be that asymmetrically processing symmetric ciphers is less cost intensive than asymmetrically processing the data itself. With small chunks of data this assumption is not true. The vastly reduce execution time this framework processes the symmetric ciphers for the data chunks independent from the data chunks; separately handled by an asymmetric cryptography approach; also independent from the data chunks; preventing the costly execution time to process each data chunk with an asymmetric cryptography approach.
Setup
A usual setup takes care that the (symmetric) ciphers are are generated by the encryption part of the framework only and being stored volatile (in-memory) by the encryption part. Those (symmetric) ciphers are published in an encrypted form to the decryption part of the framework using an asymmetric cryptography approach. The encryption part uses the public key of the decryption part for encrypting the symmetric ciphers. The decryption part may also support an asymmetric cryptography approach for providing the (symmetric) ciphers to multiple decryption services, each of which equipped with its own private key.
There are two common used types of refcodes-forwardsecrecy setup for your applications.
-
Basic setup: The basic setup encrypts the symmetric ciphers of the encryption part with the public key of the decryption part. Any decrypting participant located in the decryption part must have access to the same private key in order to make use of the encrypted ciphers.
-
Usual setup: The normal setup is similar to the basic setup with the addition that for using the ciphers on the decryption part, additional key pairs are required for each decryption participant located in the decryption part; each decrypting participant uses its own private key, a single private key must not be known by all decrypting participants.
Design
The framework design provides three layers each for the encryption part respectively the decryption part:
Provider: A provider can be an encryption provider or a decryption provider and is being used by the business logic to encrypt or decrypt texts. The business logic must not know anything about ciphers or cipher versions. For encryption or decryption a symmetric encryption approach is used
Service: The service can be an encryption service or a decryption service managing ciphers or cipher versions exclusivity in-memory for the symmetric encryption approach. For exchanging cipher versions with a data store (file-system, repository) between the encryption and the decryption systems (encryption servers and decryption servers), an asymmetric encryption approach may be used.
Server: A server can be an encryption server or a decryption server; responsible for securely storing (encryption server) or securely retrieving (decryption server) cipher versions. Hence a server is required for exchanging cipher versions between the data store (file-system, repository) and the according services; here an asymmetric encryption approach may be used for encrypting cipher versions (encryption server) and decrypting cipher versions (decryption server).
Please take a look at the drawing below for an overview on the key- and cipher-exchange process: Red regards the asymmetric key life-cycle, yellow regards the high-volume data to be encrypted and green regards the decryption process.
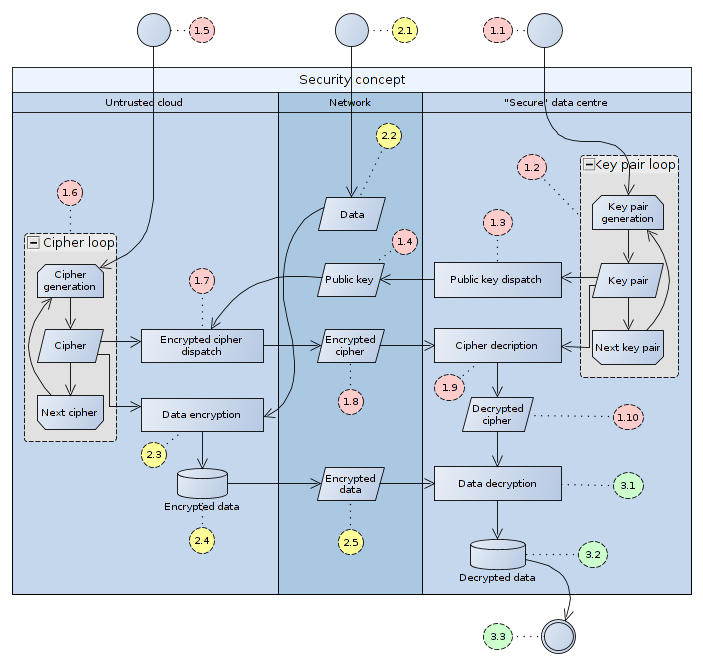 |
|---|
Overview of the refcodes-forwardsecrecy artifact’s internal functioning |
For a detailed description see chapter “10. … AND OUT OF THE CLOUD: SECURITY” in my paper on Big data processing the lean way - a case study.
Actually the complete asymmetric cipher version exchange can be handled inside the services layer so that the servers must not know anything about private or public keys (as of the basic setup). This has the shortcoming, that all decrypting services must have access to the same private key . It has the advantage, that the sever does not unveil any ciphers. Nevertheless a decryption wrapper can be (and is) implemented wrapping the decryption sever and adding additional key-pair support for cipher version exchange with the decryption services (as of the normal setup).
As we support encryption and decryption, the triple of provider, service and server exists for the encryption part as well as for the decryption part.
At a closer look, we see the following types participating in the refcodes-forwardsecrecy tool-box:
Cipher version
A
cipher versionrepresents a cipher (used for symmetric encryption respectively decryption) related to a cypher’s version (UID).
Implementation specific specializations might add attributes to determine whether a cipher version is outdated and must be replaced by a new cipher version or other attributes helpful for housekeeping and management of cipher versions. The cipher versions are (indirectly) bound to a namespace.
Namespace
A
namespaceseparates the various sets ofcipher versions semantically from each other.
An application might be bound to a namespace or a tenant of an application might be bound to a namespace (depends on the requirements). In practice this is achieved by bounding encryption providers, which are the hot spots for the business logic, to a namespace; for the business logic the namespace is transparent (it is a matter of configuration).
Encryption provider
The
encryption provideris bound to anamespaceand is being used by the business logic to encrypt data.
It is merely responsible for retrieving a currently valid cipher for encrypting data. The encryption provider does not expose the cipher though it might store it in clear text in-memory only (advanced implementations might encrypt the in-memory cipher). The (internally) retrieved cipher is requested from and provided by an encryption service (on the same machine) which takes care of providing (and creating) a cipher with a cipher UID as well as publishing the according cipher version (via the encryption server to the decryption server). As the encryption provider does not persist any data, an in-memory cipher version will only be used as long as the encryption provider is up-and-running. In case of a restart, a new cipher for encryption is requested from the encryption service. Also the encryption provider can be forced to (create and to) use a next valid cipher on demand.
Encryption service
An
encryption serviceis bound to a singlenamespaceand creates uniquecipher versions for thatnamespace.
The encryption service may make use of an encryption server persisting cipher versions per namespace. It could actually generate a dedicated cipher just once, so any unauthorized system having access to the ciphers gets a different cipher not used by any of the authorized participant. Never two participants will encrypt with the same cipher (taken the probability that two participants generate the same cipher is very low and nearly never to happen; in case it happens there is still no security risk). The key advantage is that if an intruder can also retrieve ciphers, those ciphers being retrieved are never used by other systems for encryption as a cipher version is bound to the requester.
To later determine which cipher to use when decrypting data, each cipher has a cipher UDI assigned to it (a cipher UID and cipher make up a cipher version). Encrypted data is prefixed with this cipher UID so later it is easy to determine which cipher is responsible for decryption. The cipher UID is assumed to be public as it’s generation must be completely independent from the cipher itself. Unauthorized systems having access to the cipher UID cannot reverse calculate the cipher
There is not even a relation between cipher and cipher UID in terms if hash code. This means using brute force approaches with rainbow tables or whatsoever to reconstruct the cipher from the cipher UID is to fail.
Depending on the implementation, the encryption service makes use of a public key of an asymmetric encryption approach for encrypting the cipher versions; to be persisted by the encryption server.
Encrypting only the cipher is sufficient, the cipher UID can be stored in plain text; it securely can be assumed to be public. As said before, any intruder knowing the cipher UIDs does not weaken the forward secrecy cryptography infrastructure as knowing the cipher UIDs is only of use with the according ciphers; which cannot be calculated from the cipher UIDs.
Encryption server
The
encryption servertakescipher versions generated by anencryption servicefor a providednamespace.
A cipher version provided to the encryption server (by an encryption service) is persisted so that the decryption server can access this cipher version. When persisting, a cipher version’s cipher UID is verified whether there is already a cipher version with the same cipher UID already persisted and where necessary rejected (such collisions can be avoided with good cipher UIDs).
Regarding the implementation of the encryption server, securely persisting can be done with the public key of an asymmetric encryption approach so that only the decryption service can get the plain text ciphers from the cipher versions. To avoid transmitting plain text cipher versions from the encryption service to the encryption server, the encryption service should already encrypt the cipher version with the according public key so that the encryption server always receives encrypted cipher versions.
The forward secrecy cryptography infrastructure supports encryption servers which only need to take care of persisting the cipher versions and retrieving them. Encryption and decryption can be done in the according service layers. E.g. the encryption service uses a public key to encrypt the cipher of a cipher versions and passes it to the encryption server just storing the cipher version without any additional encryption. A decryption service in turn requests the cipher versions with the encrypted ciphers from the decryption server and is decrypting the ciphers with the according private key. Another more complex approach is described regarding the decryption server.
By replacing the implementation of the
encryption server, the waycipher versions are persisted can be changed easily.
Decryption server
The
decryption servercontainscipher versions assigned to anamespace.
Depending on the implementation, the decryption server might as well contain a number of public keys (for an asymmetric encryption approach) also assigned to the individual namespaces identifying the owners of the private keys with which it is secure to communicate.
The decryption server might access persisted cipher versions. Depending on the implementation, the cipher versions to be persisted must be encrypted with the decryption server’s public key. An encryption service having this public key then can do secure persisting.
Requesting the cipher versions from the decryption server might then be done by authenticating that the requester is entitled to request the cipher versions by verifying the signature of a requester’s message with the public keys by the decryption server and by encrypting the cipher versions with that according public key. The decryption server itself might use an asymmetric encryption approach to decrypt persisted cipher versions persisted by the encryption server (and being encrypted by the encryption service).
A decryption server’s wrapper could be hooked on top the decryption server which uses the private key used for encrypting the ciphers by the encryption service to decrypt the ciphers and encrypts the ciphers again with a public key from a key pair of an according decryption service. The decryption service authenticates itself with a message and a message’s signature generated from its according private key. The decryption server can validate the signature and use the trusted public key for encryption. By replacing the implementation of the decryption server, the way cipher versions are persisted can be changed easily.
Decryption service
A
decryption serviceis bound to a singlenamespaceand providescipher versions required for decrypting text by thedecryption provider
The decryption service may make use of a decryption server managing the cipher versions per namespace.
Depending on the implementation, the decryption service has a private key for an asymmetric encryption approach whose public counterpart is used by the encryption service. This private key then is used to decrypt the ciphers form the retrieved cipher versions.
A decryption server’s wrapper may be hooked on top of the decryption server containing public keys known as being trusted and the private key for decrypting ciphers being encrypted by the encryption service. When cipher versions are being requested by a decryption service from the wrapped decryption server, the decryption service authorizes itself by signing a message with a signature passed to the decryption server. In case the message’s signature is verified by the decryption server with one of its trusted public keys, then the public key in question is used by the decryption server for encrypting the cipher versions being transmitted to the decryption service.
Decryption provider
The
decryption provideris bound to anamespaceand is being used by the business logic to decrypt data.
The decryption provider provides decrypting functionality as encrypted data must be decrypted again by another service or system. This system must now be able to retrieve all known ciphers versions (by a decryption service) for determining the correct cipher for decrypting encrypted text (as encrypted text is prefixed by the cipher UID identifying the cipher to use for decryption).
Cipher version factory
Cipher version factories manufacture
cipher versionsand make the creation of those replaceable.
As requirements might arise to use cipher versions with additional attributes or functionality; the cipher version factory can be replaced with a custom implementation instantiating cipher version (sub-)types with the additional required attributes or functionality. Additional attributes might be a validity date useful for housekeeping or management purposes.
In case you provide your custom cipher version factory implementation, make sure the cipher version (sub-)type you return fits with the cipher version (sub-)type of your custom cipher version generator. A good approach is to make your custom cipher version generator make use your custom cipher version factory (see the default implementations of the cipher version generator and cipher version factory).
Cipher version generator
Depending on the security demands and performance issues; the generator generating cipher versions can be replaced with a custom cipher version generator using its own approach generating ciphers and cipher UIDs (cipher versions).
In case you provide your custom cipher version generator implementation, make sure the cipher version (sub-)type you return fits with the cipher version (sub-)type of your custom cipher version factory. A good approach is to make your custom cipher version generator make use your custom cipher version factory (see the default implementations of the cipher version generator and cipher version factory).
Snippets of interest
Below find some code snippets which demonstrate the various aspects of using the refcodes-forwardsecrecy artifact (and , if applicable, its offsprings). See also the example source codes of this artifact for further information on the usage of this artifact.
A first setup
First we prepare our local setup: Therefore for the decryption part we use the InMemoryDecryptionServer type:
1
2
3
InMemoryDecryptionServer theDecryptionServer = new InMemoryDecryptionServer();
DecryptionService theDecryptionService = new PublicKeyDecryptionService( "myNameSpace", "/path/to/private/key", theDecryptionServer, 500 );
DecryptionProvider theDecryptionProvider = new DecryptionProviderImpl( theDecryptionService );
As we have a local setup here, we use the InMemoryDecryptionServer instance to setup the encryption part’s InMemoryEncryptionServer instance:
1
2
3
InMemoryEncryptionServer theEncryptionServer = new InMemoryEncryptionServer( theDecryptionServer );
EncryptionService theEncryptionService = new PublicKeyEncryptionService( "myNameSpace", "/path/to/public/key", theEncryptionServer );
EncryptionProvider theEncryptionProvider = new EncryptionProviderImpl( theEncryptionService );
In a distributed environment, we would use the
FileSystemEncryptionServertype for the encrypting part and theFileSystemDecryptionServertype for the decrypting part (or according custom implementation of theDecryptionServertype alongside the counterpartEncryptionServertype)!
Mass forward secrecy
Here again we go for local setup, in a distributed environment we would split the encryption part from the decryption part in propably two services:
1
2
3
4
5
6
7
for ( ... ) {
theEncryptionProvider.nextCipherVersion();
String theEncryptedText = theEncryptionProvider.toEncrypted( theText );
...
String theDecryptedText = theDecryptionProvider.toDecrypted( theEncryptedText );
...
}
In a real world setup, encryption logic (line 3) and decryption logic (line 5) would reside on different services!
Resources
The whole encryption process is illustrated in chapter “10. … AND OUT OF THE CLOUD: SECURITY” in my paper on Big data processing the lean way - a case study (Slides) at the Coding Serbia 2014 conference.
Contribution guidelines
- Report issues
- Finding bugs
- Helping fixing bugs
- Making code and documentation better
- Enhance the code
Who do I talk to?
- Siegfried Steiner (steiner@refcodes.org)
Terms and conditions
The REFCODES.ORG group of artifacts is published under some open source licenses; covered by the refcodes-licensing (org.refcodes group) artifact - evident in each artifact in question as of the pom.xml dependency included in such artifact.